做了几年PHP,老板、经理没说让我管过日志这东西。一般牵涉到日志运维这主要是运维的工作。但是这一章节主要是以拔高性质为主。分析日志的管理方式。PHP程序员不能光靠PHP成为高手,PHP不就if else那几样吗?光靠PHP是不行的。

说明该server(虚拟主机),它的访问日志的文件是 logs/host.access.log

remote_addr是远程地址。你去面试的时候经常会碰到一些问题:启动pid去获取来访者的远程ip信息,$remote_user [$time_local]远程的用户访问的时间,当然我访问的那一瞬间我的http头信息未必带了这个信息过去,没带过去那就没有空着。

请求分GET和POST,请求都是用GET来请求。remote_user远程用户,并没有用http头交互说我是谁的那个形式,就是405还有权限验证那个玩意。就是我remote_user为空,但是time_local记录下来了。你当时几点几分来访问,用什么样的请求头来访问的,或者说是请求形式来请求的,用的是GET方式来请求的,而且用的是HTTP1.1这个协议。Status是请求的状态,学过HTTP协议知道有:200(OK),304(Not Modified),404(Not Found),403(Forbidden)。刚才几次访问的状态是404,304和200全了。body_bytes_sent就是我给你的几个主体发送几个字节。有570个字节,168个字节,32个字节,0个字节和46个字节。http_referer,就是你上一个/上一次页面来自于哪里,上一个页面来自于哪里。为什么有时候我们登录别人的网站,尤其是统计类的网站,统计说,咱们这个会员、咱们这个用户登录都来自于哪里。它这个统计怎么知道咱们这个会员是从百度来的呢,是从360来的呢,是从搜狗来的呢,它是如何知道的呢?




这是因为你在百度上一搜,比如搜php培训,你一点某个词条,你当前停留在哪里?你当前停留在百度,你一点带了一个referer信息过去,所以咱们这个统计就知道你来自于哪里。百度,你从百度搜索过来的。以后咱们做文件的防盗链和图片的防盗链也是要靠referer信息。
user_agent,用户代理。你去请求的时候,浏览器帮我们发的请求,我们想读人家的网页,但是我们无法跑人家服务器上读人家的字节,0101这样去读取。我们得靠浏览器去帮忙。所以这个浏览器被称之为用户代理。一分析知道了,你是Mozilla/5.0 (Windows NT 6.1; WOW64),火狐浏览器,win 7机器,有时候见到签名那很炫,你来自于哪里哪里,什么欢迎你北京联通的用户。你使用的是火狐,就是从你referer头信息读取出来的。
x_forwarded_for。网易新闻的评论,来自朝鲜的网友说:,这个网友不是真的来自朝鲜(实际上朝鲜能不能上网还是个问题)。

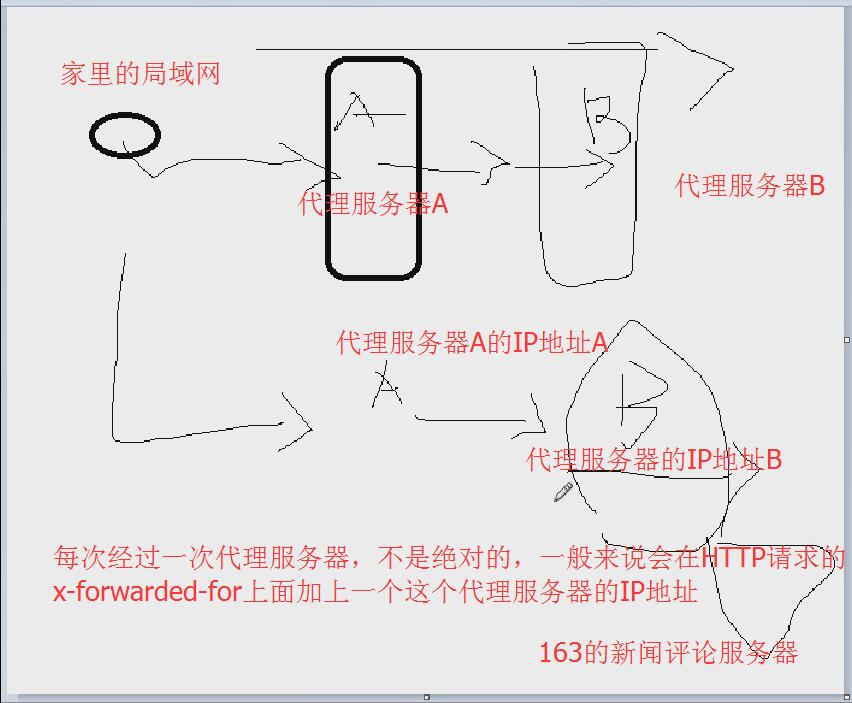
163会拿最后一次的x-forwarded-for来做判断,一判断说哦,来自于朝鲜的用户。
以后你要想伪装自己的IP,你也可以用x_forwarded_for来伪装一下。但是有些机器不看你x_forwarded_for,就直接看你的remote_addr。这个时候主动权在服务器端,看它以哪一个为准了。
所以这就是日志的main格式。你要是看这个格式不爽,可以把main格式的变量自由组合,去掉几个也行。main格式只是一种拿着几个变量组合的一种形式而已。
刚才user_agent只说了一半,有时候一读你的日志发现不对劲,既不是火狐,也不是IE,也不是chrome,这个有可能是蜘蛛。蜘蛛爬到你的服务器上去了,你需要买一些bus消毒液和一些除蟑螂的药等等,把你的服务器彻底清理一下。网络上有一种机器叫做蜘蛛,其实就是搜索引擎的服务器。它们的服务器一天到晚没事就沿着网络上的链接到处走到处爬,把你的信息都给爬取出来。有一种协议叫做蜘蛛协议,有些人老是过来采集我的信息,你到底是谁,我把你封了。所以这个时候百度说:别封,我是百度蜘蛛。所以User-agent叫Baiduspider,谷歌叫Googlebot,MSN叫MSNBot。Disallow是不允许扫的地址。

/shifen/原来是百度竞价,怪不得不允许人家扫。

这个蜘蛛是要满足一定的协议的,这个协议不是强制的,只能靠道德去规范。淘宝三年前把百度的蜘蛛给屏蔽了,你在百度上搜淘宝它的链接信息就比较少。这个时候就不能去索引它的信息了。技术上耍赖肯定行,人家只是说不让你搜,你要硬搜别人也很难挡住,除非屏蔽你的IP地址。因为目前蜘蛛只是一个协议,所以有时候在自己的日志上看到Baiduspider,你就知道百度蜘蛛来光顾你了,说明你的网站质量还不错。

每个网站它访问的日志不一样啊,分开放是天经地义的,但是有的WEB服务器不支持。比如像lighttp它就不支持。

到底如何配置访问日志呢?
刚才我也没配置任何的访问日志,为神马logs下面还会有访问access.log。很简单,因为你系统一启动它默认就使的是main格式,而且是放在logs/access.log下面。那你要是自己配置了它就有自己独特的日志了。说了那么多其实一句话搞定,之前的都是铺垫。



软重启nginx服务出错

main格式被注释掉了,解开它的注释



然后刷多几次网站z.com的访问量

可以查看到网站z.com的访问日志了,都是来自于IP:192.168.118.1的访问。

有时候会发现网站的访问量急剧上升,心中一阵暗喜,但后来发现所有的访问量都来自于IP某某某某,这个时候你不要高兴。要不就是蜘蛛疯狂地爬你的网站,有时候蜘蛛疯狂地爬也能把一个网站爬崩溃的,蜘蛛很强大。还有一种情况就是来自于你的竞争对手的攻击,看你的网站很火,用两台机器不断地朝你的服务器/网站发送请求,就好比说这个人买了三部电话轮流拨你的手机,那你的手机疲于应付了,这不就是攻击你吗?要想分析谁攻击我,怎么防范,这个时候就得从日志着手,分析它的来源,以及它的请求的页面,看看是先把它的IP给封住,或者把它的请求、把特别敏感的页面给暂停啊等等。所以这就是关于它的日志的配置。
日志还牵涉到运维的工作,那这个日志哪里体现出运维了呢?如果我的网站访问量比较大,那有可能一个小时两个小时都积累很多了,一天下来这个日志得一个GB,一天一个GB的访问量一点不夸张。这个日志要是一直都存在一个文件里面,那肯定是:第一你后期不好处理日志,个个日志都十几个GB这么大你怎么处理啊。不好读啊,技术员一打开就卡死了。另外不好管理不好归档,希望每天的日志能按照日期备份,每天产生一个新日志,思路是:

再加上Linux的定时任务,那么同学们先把这个任务研究一下。下节课讲定时任务和日志切割。